Chapter 7: Amazon DynamoDB
DynamoDB is the Amazon "DC" only (simple) database for NoSQL.
The sort of bike dynamo I had as a kid (worked ok, made a terrible racket, terrible wear on the tyres, and slowed you down!)

So what's this NoSQL stuff?

NoSQL actually stands for "Not just" SQL rather than "Not" SQL. The certification book just leaps straight into the details of DynamoDB without much introduction to the different types of databases, pros and cons, and different sub-types of NoSQL databases (lots). So I'll do the same but come back to the bigger questions later. This page has a higher level introduction, some alternatives versions and some architectural examples of applications using it. There's even a local standalone version.
The book only really covers the basics.
The Data Model is tables, items and attributes. Each item is a collection of 1 or more attributes.
The only requirement is that a table has a primary key in advance.
Each attribute is a name/value pair. An attribute can be a single or multi valued set. I.e. no order and no duplicates. So you can store book details as long as co-authors don't have identical names (are there any examples of books with identically named co-authors? Fathers and sons in USA maybe?)
There are lots of Data Types (main categories are Scalar, Set, Document). Each item that is added to the table can add additional attributes.
Tables are documented here.
Primary Key
When created each table must have a primary key (as well as table name). There are two types of primary keys: Partition key (one attribute - a partition or hash key), or partition and sort key (2 attributes - each table item is uniquely identified by combination of the 2). Each primary key attribute must be a string, number of binary.
Provisioned Capacity
When created each table must have a read/write capacity provisioned. Each operation against the table will consume some of the provisioned capacity units. The amount of capacity consumed appears to depend on various factors including amount of data, indexes, and consistency level. CloudWatch should be used to keep track of capacity as if you exceed them for a period ot time you will be throttled.
Secondary indexes can be created when the table is created with partition and sort keys, and allow searching of large tables efficiently (avoiding expensive scan operations). When an item is modified the secondary index is automatically updates which consumes write capacity units.
Writing Items
You can create, update and delete items in tables. update has support for atomic counters which allow consistent concurrent increment/decrement of values. Write operations also support conditional expressions that perform a validation before the operation is carried out.
Reading Items
Items can be retrieved with the GetItem or a search using Query or Scan actions.
GetItem consumes read capacity units based on the size and consistency option. By default it uses a eventually consistent read, but you can request a strongly consistent read instead (which consumes more capacity).
There are batch operations which operate on 25 items at once.
Scaling and Partitioning
DynamoDB uses partitions to scale horizontally to meet storage and performance requirements.
Each partition represents a unit of compute and storage capacity: 10GB of data and 3,000 read capacity units or 1,000 write capacity units. Capacity is managed and provides bursts or throttling over time.
If storage or performance requirements change over time a partition can be split BUT CANNOT BE MERGED AGAIN. Also to ensure full capacity can be used ensure that the workload is evenly spread across the partition key values. If you are hitting a single partition key you won't be able to get more than 3,000 read capacity units. You need to create tables with partition keys that have a large number of distinct values and request them uniformly. You can do this by adding a random element.
Note: It would be nice if DynamoDB was just "Elastic" and could scale up and down automagically without having to worry about capacity units, bursting, throttling and key management. From a s/w architecture perspective some of this is a bit low level, but still very interesting from computer science and performance engineering angles. Maybe Elastic Beanstalk helps?
Finally there is DynamoDB Streams. These keep track of changes and produce streams (organised around groups called shards). To build an application reading from a shard use the Kinesis Adapter and the Kinesis Client Library (KCL). At one level this appears a bit "odd" as a stream event processing system normally processes real-time streaming events and processes it on the fly before deciding to persist it etc. However, maybe this is more like a Kappa architecture (an "inside-out" db, which has an immutable data store before the complex event processing takes place?
PS
One of the big advantages of SQL was that it provided a standard abstraction for programming applications against, and if you didn't want to program directly in SQL (who did?) then there were other higher level abstractions available such as language specific persistence frameworks, Java Enterprise container managed persistence (CMP), Hibernate, etc. These tended to allow for specialisation in roles so if you were focussed on one role you didn't need to care about other aspects (i.e. data management, programming and business logic, deployment to production environment, configuration, etc).
It looks like there is good support for (e.g.) Java POJOs and DynamoDB which is probably the right level of abstraction for NoSQL databases and applications:
https://tech.smartling.com/getting-started-with-amazon-dynamodb-and-java-universal-language-850fa1c8a902
http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DynamoDBMapper.html
https://medium.com/aws-activate-startup-blog/serverless-architectures-with-java-8-aws-lambda-and-amazon-dynamodb-part-2-95ebd852d366
https://www.cdata.com/kb/tech/dynamodb-jdbc-hibernate.rst
P2S
Some references I thought were interesting (probably looking at NoSQL abstractions):
https://aws.amazon.com/nosql/
http://optimalbi.com/blog/2017/03/15/dynamodb-vs-mongodb-battle-of-the-nosql-databases/
http://cloudacademy.com/blog/amazon-dynamodb-ten-things/
http://stackoverflow.com/questions/7870928/abstraction-frameworks-to-work-with-nosql-databases
http://gora.apache.org/
http://www.dataversity.net/the-nosql-movement-what-is-it/
This is a good survey of NoSQL database types (NoSQL Databases: a Survey and Decision Guidance): It has a good introduction to NoSQL categorisation dimensions, functional and non-functional requirements, techniques used for achieving them, and a decision tree for selecting appropriate solutions.
This has a useful categorization diagram in terms of where on the "CAP" spectrum they fall:
http://blog.grio.com/2015/11/sql-nosql-a-brief-history.html

P3S
Simple classifications of NoSQL databases typically include the following types:
Key-value stores
Documents stores (includings structured documents such as XML)
Graph databases (lots, these look really interesting and worth a 2nd and 3rd look, their origins go way back to pre-SQL data models)
Object databases (including ORMs)
Tabular (don't know much about these TODO)
Tuple stores (these look interesting particular in relationship to Logic Programming and Big Data?)
Triple/Quad stores (RDF?)
Big tables (Hadoop?)
Sparse tables (same?)
Unstructured data indexing and search (E.g. SPLUNK, a big index/search engine with maybe no database at all for unstructured data ingestion and querying, and Elasticsearch which is similar type of NoSQL thingy).
P4S
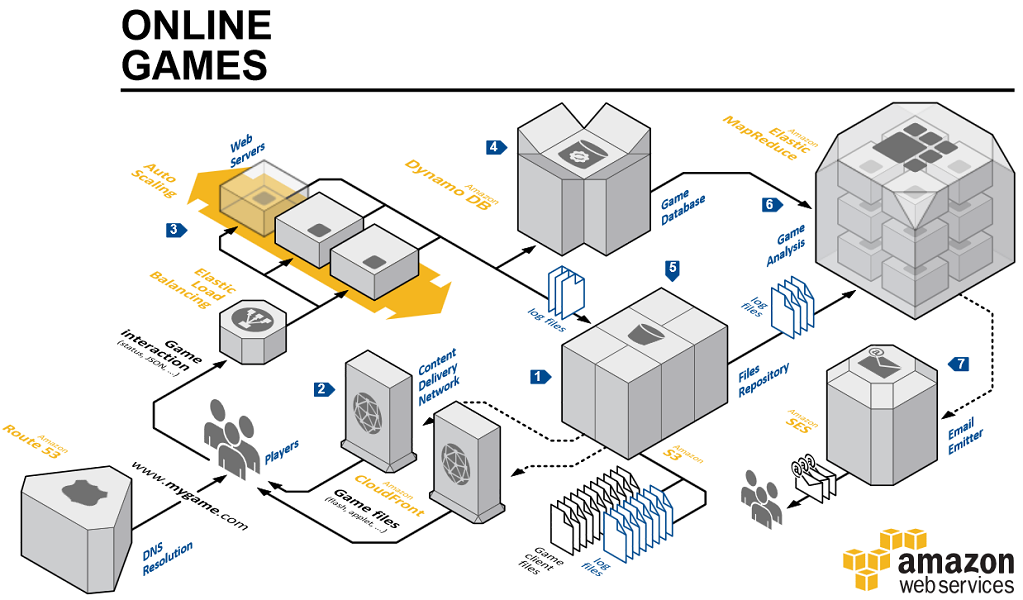
Some example reference architectures built (Spot the DynamoDB):
Advertising

Gaming
IoT

Canary
P5S
From the above architectural examples it looks like there are a number of well understood ways of integrating DynamoDB with other AWSs so I wondered what design patterns are common? Here's some:
https://www.slideshare.net/AmazonWebServices/design-patterns-using-amazon-dynamodb
A reference architecture from this link:
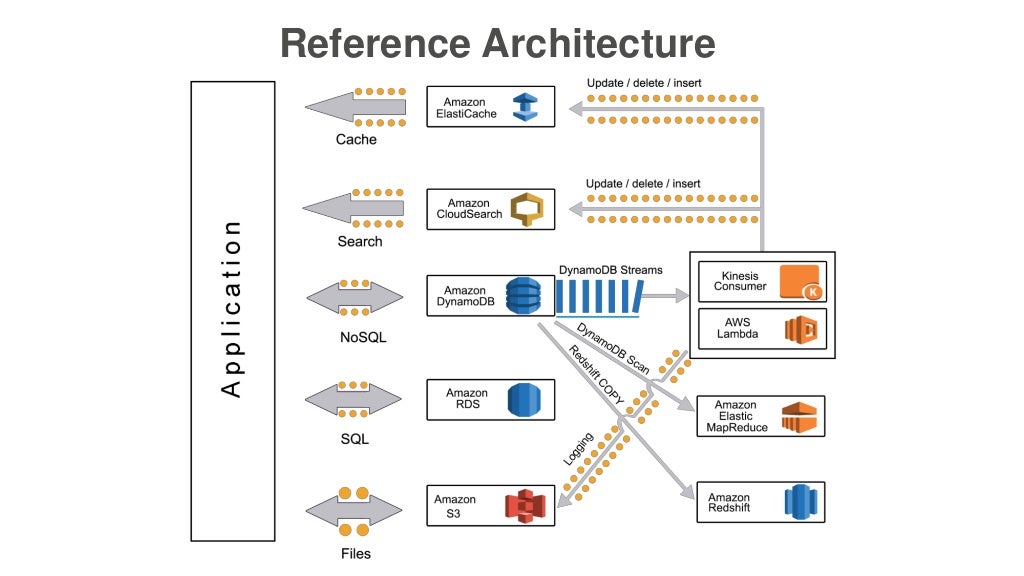
older: https://www.slideshare.net/InfoQ/amazon-dynamodb-design-patterns-best-practices
A book: https://www.amazon.com.au/DynamoDB-Applied-Design-Patterns-Uchit-ebook/dp/B00NVDAWSS
A webinar: https://www.youtube.com/watch?v=xV-As-sYKyg
And integration with other AWSs.
P6S
And don't forget prices and limits!
P7S
I've been thinking more about the differences between "Enterprise scale" and "Internet scale" systems. One of the obvious features of enterprise systems is that they support transactions. If you do a search for "AWS transaction" you don't find much, so this is an obvious difference. However, there does appear to be support for transactions for DynamoDB. For example:
DynamoDB transaction library
And these guys document some of the shortcomings with DynamoDB including lack of transactional support (with a solution based on caching mapper) and performance limits.
The sort of bike dynamo I had as a kid (worked ok, made a terrible racket, terrible wear on the tyres, and slowed you down!)

So what's this NoSQL stuff?
NoSQL actually stands for "Not just" SQL rather than "Not" SQL. The certification book just leaps straight into the details of DynamoDB without much introduction to the different types of databases, pros and cons, and different sub-types of NoSQL databases (lots). So I'll do the same but come back to the bigger questions later. This page has a higher level introduction, some alternatives versions and some architectural examples of applications using it. There's even a local standalone version.
The book only really covers the basics.
The Data Model is tables, items and attributes. Each item is a collection of 1 or more attributes.
The only requirement is that a table has a primary key in advance.
Each attribute is a name/value pair. An attribute can be a single or multi valued set. I.e. no order and no duplicates. So you can store book details as long as co-authors don't have identical names (are there any examples of books with identically named co-authors? Fathers and sons in USA maybe?)
There are lots of Data Types (main categories are Scalar, Set, Document). Each item that is added to the table can add additional attributes.
Tables are documented here.
Primary Key
When created each table must have a primary key (as well as table name). There are two types of primary keys: Partition key (one attribute - a partition or hash key), or partition and sort key (2 attributes - each table item is uniquely identified by combination of the 2). Each primary key attribute must be a string, number of binary.
Provisioned Capacity
When created each table must have a read/write capacity provisioned. Each operation against the table will consume some of the provisioned capacity units. The amount of capacity consumed appears to depend on various factors including amount of data, indexes, and consistency level. CloudWatch should be used to keep track of capacity as if you exceed them for a period ot time you will be throttled.
Secondary indexes can be created when the table is created with partition and sort keys, and allow searching of large tables efficiently (avoiding expensive scan operations). When an item is modified the secondary index is automatically updates which consumes write capacity units.
Writing Items
You can create, update and delete items in tables. update has support for atomic counters which allow consistent concurrent increment/decrement of values. Write operations also support conditional expressions that perform a validation before the operation is carried out.
Reading Items
Items can be retrieved with the GetItem or a search using Query or Scan actions.
GetItem consumes read capacity units based on the size and consistency option. By default it uses a eventually consistent read, but you can request a strongly consistent read instead (which consumes more capacity).
There are batch operations which operate on 25 items at once.
Scaling and Partitioning
DynamoDB uses partitions to scale horizontally to meet storage and performance requirements.
Each partition represents a unit of compute and storage capacity: 10GB of data and 3,000 read capacity units or 1,000 write capacity units. Capacity is managed and provides bursts or throttling over time.
If storage or performance requirements change over time a partition can be split BUT CANNOT BE MERGED AGAIN. Also to ensure full capacity can be used ensure that the workload is evenly spread across the partition key values. If you are hitting a single partition key you won't be able to get more than 3,000 read capacity units. You need to create tables with partition keys that have a large number of distinct values and request them uniformly. You can do this by adding a random element.
Note: It would be nice if DynamoDB was just "Elastic" and could scale up and down automagically without having to worry about capacity units, bursting, throttling and key management. From a s/w architecture perspective some of this is a bit low level, but still very interesting from computer science and performance engineering angles. Maybe Elastic Beanstalk helps?
Finally there is DynamoDB Streams. These keep track of changes and produce streams (organised around groups called shards). To build an application reading from a shard use the Kinesis Adapter and the Kinesis Client Library (KCL). At one level this appears a bit "odd" as a stream event processing system normally processes real-time streaming events and processes it on the fly before deciding to persist it etc. However, maybe this is more like a Kappa architecture (an "inside-out" db, which has an immutable data store before the complex event processing takes place?
PS
One of the big advantages of SQL was that it provided a standard abstraction for programming applications against, and if you didn't want to program directly in SQL (who did?) then there were other higher level abstractions available such as language specific persistence frameworks, Java Enterprise container managed persistence (CMP), Hibernate, etc. These tended to allow for specialisation in roles so if you were focussed on one role you didn't need to care about other aspects (i.e. data management, programming and business logic, deployment to production environment, configuration, etc).
It looks like there is good support for (e.g.) Java POJOs and DynamoDB which is probably the right level of abstraction for NoSQL databases and applications:
https://tech.smartling.com/getting-started-with-amazon-dynamodb-and-java-universal-language-850fa1c8a902
http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DynamoDBMapper.html
https://medium.com/aws-activate-startup-blog/serverless-architectures-with-java-8-aws-lambda-and-amazon-dynamodb-part-2-95ebd852d366
https://www.cdata.com/kb/tech/dynamodb-jdbc-hibernate.rst
P2S
Some references I thought were interesting (probably looking at NoSQL abstractions):
https://aws.amazon.com/nosql/
http://optimalbi.com/blog/2017/03/15/dynamodb-vs-mongodb-battle-of-the-nosql-databases/
http://cloudacademy.com/blog/amazon-dynamodb-ten-things/
http://stackoverflow.com/questions/7870928/abstraction-frameworks-to-work-with-nosql-databases
http://gora.apache.org/
http://www.dataversity.net/the-nosql-movement-what-is-it/
This is a good survey of NoSQL database types (NoSQL Databases: a Survey and Decision Guidance): It has a good introduction to NoSQL categorisation dimensions, functional and non-functional requirements, techniques used for achieving them, and a decision tree for selecting appropriate solutions.
This has a useful categorization diagram in terms of where on the "CAP" spectrum they fall:
http://blog.grio.com/2015/11/sql-nosql-a-brief-history.html
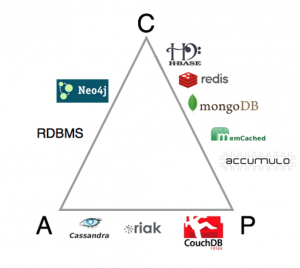
P3S
Simple classifications of NoSQL databases typically include the following types:
Key-value stores
Documents stores (includings structured documents such as XML)
Graph databases (lots, these look really interesting and worth a 2nd and 3rd look, their origins go way back to pre-SQL data models)
Object databases (including ORMs)
Tabular (don't know much about these TODO)
Tuple stores (these look interesting particular in relationship to Logic Programming and Big Data?)
Triple/Quad stores (RDF?)
Big tables (Hadoop?)
Sparse tables (same?)
Unstructured data indexing and search (E.g. SPLUNK, a big index/search engine with maybe no database at all for unstructured data ingestion and querying, and Elasticsearch which is similar type of NoSQL thingy).
P4S
Some example reference architectures built (Spot the DynamoDB):
Advertising
Gaming
IoT
Canary
P5S
From the above architectural examples it looks like there are a number of well understood ways of integrating DynamoDB with other AWSs so I wondered what design patterns are common? Here's some:
https://www.slideshare.net/AmazonWebServices/design-patterns-using-amazon-dynamodb
A reference architecture from this link:
older: https://www.slideshare.net/InfoQ/amazon-dynamodb-design-patterns-best-practices
A book: https://www.amazon.com.au/DynamoDB-Applied-Design-Patterns-Uchit-ebook/dp/B00NVDAWSS
A webinar: https://www.youtube.com/watch?v=xV-As-sYKyg
And integration with other AWSs.
P6S
And don't forget prices and limits!
P7S
I've been thinking more about the differences between "Enterprise scale" and "Internet scale" systems. One of the obvious features of enterprise systems is that they support transactions. If you do a search for "AWS transaction" you don't find much, so this is an obvious difference. However, there does appear to be support for transactions for DynamoDB. For example:
DynamoDB transaction library
And these guys document some of the shortcomings with DynamoDB including lack of transactional support (with a solution based on caching mapper) and performance limits.



Great... Excellent sharing... This is very helpful for beginners. Read that provide me more enthusiastic. This helps me get a more knowledge about this topic. Thanks for this.hunt aws jobs in hyderabad
ReplyDeleteThis blog gives good info I really enjoy this post
ReplyDeleteAWS Online Course Hyderabad
nice information on data science has given thank you very much.
ReplyDeleteData Science Course in Hyderabad
nice information
ReplyDeleteAWS Training
AWS Online Training
Your blog is in a convincing manner, thanks for sharing such an information with lots of your effort and time
ReplyDeletemongodb online training India
mongodb online training Hyderabad
I really liked your blog post.Much thanks again. Awesome.
ReplyDeleteOSB online training
OSB training
OTM online training
OTM training
SAS online training
SAS training
structs online training
structs training
Webmethods online training
Webmethods training
Wise package studio online training
angular js online training
ReplyDeletesql server dba online training
oracle golden gate online training
This post is so interactive and informative.keep updating more information...
ReplyDeleteAws Training In Mumbai
Aws Training In Ahmedabad
Aws Training In Kochi
Aws Training In Trivandrum
Aws Training In Kolkata
AWS Solution Architect
AWS
Our team of experienced instructors comprises industry veterans and certified AWS Course in Noida professionals who are passionate about teaching and dedicated to your success. With their guidance and mentorship, you'll receive personalized attention and support throughout your learning journey.
ReplyDeleteexcellent blog. thanks for sharing. aws course in pune
ReplyDelete