Chapter 14: Architecture Best Practices (Chapter 0???)
A Software Architecture Approach to AWS?
I'm almost all the way through the AWS solution architecture certification book (Blog hasn't caught up reading/study sorry!) and came across the final Chapter 14. This just proves the old adage which is to always read the last page/chapter first (actually never do this). This chapter highlights the AWS tenets of architecture best practice (see various online AWS documents), but also introduces a sample business problem with iterative architectural solutions and services used.Personally I would make this "Chapter 0", and introduce a couple of "business problems", maybe some traditional architecture in-house solutions, and then show mow they can be re-architected top-down with new Amazon services introduced at a high level initially, and details only added when required. I would pick say 3 use cases (n-tier enterprise web application, data analytics, something else, maybe online multi-player game?) and then follow a top down decomposition of each solution looking at pros and cons of each AWS alternative. This would also address the issue of how you architect with Price and Limitations explicitly in mind. Some of the options just won't add up for the business or non-functional QoS requirements in terms of price and limitations without considering architectural and service alternatives. From this would also come an obvious introduction to design patterns in AWS, and eventually some of the lower level service details (that I think were introduced too early, are too complex and pedantic, and are more appropriate for DevOps, Systems and Networks administration speciality roles).
Maybe some of the AWS reference architectures would be good example (of the end architecture, would need motivating with an initial problem and draft architecture).
A couple of thoughts at this point.
The 1st tenet is well known, Design for Failure, and quotes Werner Vogels "Everything fails, all the time". Although this makes me wonder that, if taken literally, then doesn't it follow that "Nothing works, any of the time? Odd again that no-one appears to have taken things this literally, except perhaps someone on the "Kentucky Hunting" blog who said:
Nothing works all the time. Sometimes, nothing works any of the time.
However, others have thought of this general drift, which is how much (and which parts) of the AWS infrastructure, services, and your application components can you kill before your application starts to degrade or fail, and how long will it all take to come up again, assuming it's not just a local (single AZ) failure but has impacted 100s of users and multiple AZs etc? E.g. this SEI blog on chaos monkeys all the way through their bigger primate relatives, introduces the (originally Netflix) idea of testing (without warning) AWS at very levels all the way up to a whole AZ with chaos Gorillas.

DevOps
The worked example in this chapter is also a bit simplistic and appears to focus purely on production reliability/availability. There's a bit more to the story these days as DevOps needs to be factored in. This is actually what prompted me to write this blog on Blue, Green, A, B, Canaries etc.Service Discovery
And Eureka, finally on page 398 under the section on "Loose Coupling" the question of service discovery is raised (but not answered). This is one of the 1st few fundamental questions I asked myself when I started learning AWS - i.e. how do you register discover, bind, and consume services in AWS, but I couldn't find an obvious answer at the time. My people (including some AWS solutions architects) suggested things like "read the documentation" etc which to me missed the point. Most enterprise SOA/Grid/ESB systems I've worked with in the past make service discover a first-order feature and component. What am I missing here?There is a list of AWS endpoints: http://docs.aws.amazon.com/
And an approach for service discovery for ECS: https://aws.amazon.com/blogs/compute/service-discovery-an-amazon-ecs-reference-architecture/
https://aws.amazon.com/blogs/compute/service-discovery-for-amazon-ecs-using-dns/
However, none of these answer the question of how best to do application level service publication and discovery in AWS.
There is an Application discovery service, but it's for migration to AWS:
https://aws.amazon.com/application-discovery/
This article from 2015 implies that service registries are still part of the picture for microservices at least:
https://www.nginx.com/blog/service-discovery-in-a-microservices-architecture/
This appears to be the right rabbit hole (who knows where it leads):
https://aws.amazon.com/blogs/developer/serverless-service-discovery-part-1-get-started/
https://d0.awsstatic.com/whitepapers/microservices-on-aws.pdf
https://s3.amazonaws.com/amazonecs-reference-architectures/service-discovery/ecs-refarch-service-discovery.pdf
The AWS solution is to make a discovery service from other AWS services (e.g. Route 53, ELB, Lambda, Cloudwatch, CloudTrail):
https://aws.amazon.com/blogs/compute/service-discovery-an-amazon-ecs-reference-architecture/
In summary:
The technical details are as follows: we define an Amazon CloudWatch Events filter which listens to all ECS service creation messages from AWS CloudTrail and triggers an Amazon Lambda function. This function identifies which Elastic Load Balancing load balancer is used by the new service and inserts a DNS resource record (CNAME) pointing to it, using Amazon Route 53 – a highly available and scalable cloud Domain Name System (DNS) web service. The Lambda function also handles service deletion to make sure that the DNS records reflect the current state of applications running in your cluster.

And a bigger picture.
PS
There are a few surprises in this chapter as some services are mentioned (e.g. in the review questions) but they haven't been covered in the book. For example, EFS, and API Gateway. Possibly they aren't in the current course because they are recent services?
EFS
Elastic File System (not service) answers one of my 1st questions when I started reading the book which was "Why isn't there a SAN service" I.e. a storage device that will connect to 2 or more EC2 instances. This is the 3rd type of storage device, instance storage (transient), ELB (persistent but can only be connected to 1 EC2 instance at a time), and now EFS (persistent and can be connected to >= 1 EC2 instance at a time).
It's difficult to find definitive comparison in once place. The EFS FAQ compares EFS with EBS:
https://aws.amazon.com/efs/faq/
And this blog compares instance stores with EBS: Instance store cf EBS
All the current AWS storage options are covered in the white paper, but there's no simple comparison. TODO Maybe I should do one...
AWS API Gateway service
The API Gateway service is a newish service that I did come across at the AWS Sydney summit and is worth investigating further, particularly in the context of using it to trigger Lambda functions from incoming REST calls. It also looks like is has some features of ESBs to make integration with and calling back end services easier. The limits and pricing.
P2S
An important background idea for architecting for the cloud is also "architecting for internet scale".
An early (in cloud terms) work report pros/cons for internet scale cloud reports that unavailability needs to be taken into account: https://www.researchgate.net/publication/221237375_Implementing_and_operating_an_internet_scale_distributed_application_using_service_oriented_architecture_principles_and_cloud_computing_infrastructure
Even earlier is this paper on an internet scale event based system: https://www.doc.ic.ac.uk/~alw/doc/papers/esec97b.pdf
Internet scale Big Data: https://resources.sei.cmu.edu/asset_files/WhitePaper/2014_019_001_90915.pdf
This paper referred to by this check list.
Perhaps a more worrying thought is "Is the internet a scale free network?" See, now you've thought that thought it won't go away will it?!
Maybe it isn't (does it matter? Probably). Some links:
This is a really good intro to scale free and other networks that go bump in the night.
From this cool website (if you are fast enough to catch the dots).
And this blog referring to this 2009 paper.
Also interesting.
Put simply this computerworld article explains:
"Because of these differences, the two types of networks behave differently as they break down. The connectedness of a randomly distributed network decays steadily as nodes fail, slowly breaking into smaller, separate domains that are unable to communicate.
Scale-free networks, on the other hand, may show almost no degradation as random nodes fail. With their very connected nodes, which are statistically unlikely to fail under random conditions, connectivity in the network is maintained. It takes quite a lot of random failure before the hubs are wiped out, and only then does the network stop working. (Of course, there's always the possibility that the very connected nodes would be the first to go.)
In a targeted attack, in which failures aren't random but are the result of mischief, or worse, directed at hubs, the scale-free network fails catastrophically. Take out the very connected nodes, and the whole network stops functioning. In these days of concern about cyberattacks on the critical infrastructure, whether the nodes on the network in question are randomly distributed or are scale-free makes a big difference." (My emphasis)
And a picture from Nature of an exponential vs. scale free network (TODO Is exponential the same as random, I think so...)

And a picture from Nature of an exponential vs. scale free network (TODO Is exponential the same as random, I think so...)

with text.
And picture from computerworld (quoting Nature), first is exponential/random, second is scale-free.
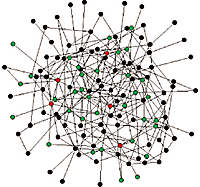
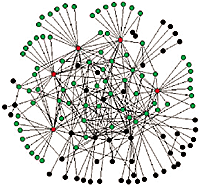
And given my recent background in modelling and simulation I thought this book looks interesting, although it may be too focussed on traffic control at network layers (but it does refer to "cloud" many times).
Actually I guess the real question is if application running on cloud and internet are scale free or not (rather than the underlying network).



Nicely explain all aspects of AWS... I found an AWS alternative and really love to use this alternative.
ReplyDeletemicroservices architecture AWS
ReplyDeleteTransform your legacy application with a microservices architecture that breaks your application into small components independent from each other.
to get more - https://microservices.nitorinfotech.com/