AWS Application Discovery Service - great minds think alike?

Reading about the AWS Application Discovery Service gave me a feeling of deja vu today.
AWS Application Discovery Service helps Systems Integrators quickly and reliably plan application migration projects by automatically identifying applications running in on-premises data centers, their associated dependencies, and their performance profile.
This sounds remarkably like one of the applications of our predictive analytics tool: for predicting performance, resource requirements and impact of changes for cloud migrations.
It supports two approaches:
Q: Should I use agentless and agent-based application discovery?
Agentless Application Discovery is recommended for VMware customers because it does not require customers installing an agent on each host, and gathers server information regardless of the operating systems. It does not collect software and software dependencies or work on non-VMware environments.
If you run a non-VMware environment, and/or are looking for software details and interdependencies, use the agent-based Application Discovery. You can run agent-based and agentless Application Discovery simultaneously.
And the data can be stored in AWS
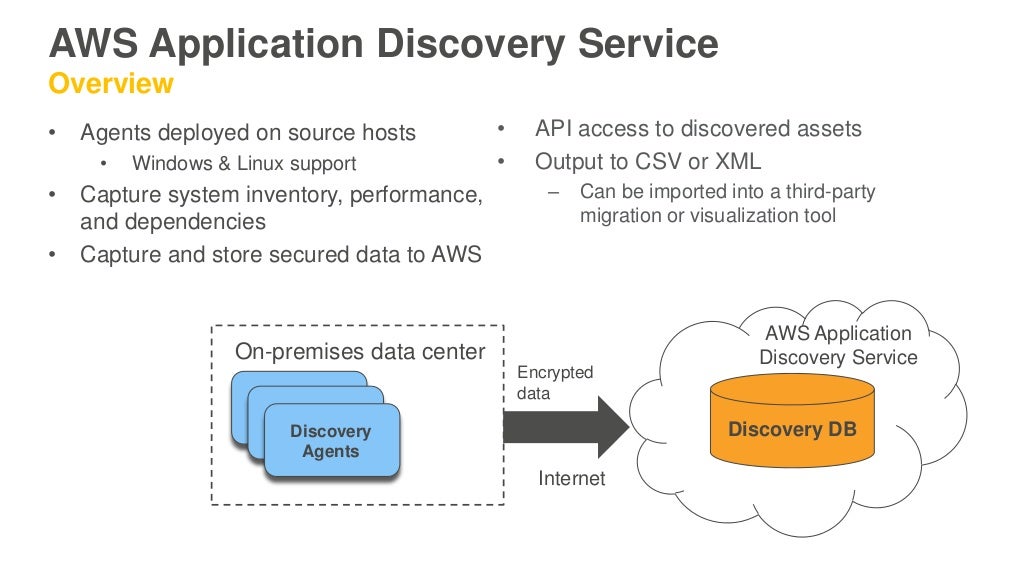
Based on our experience with attempting to get APM data out of government systems this could be a significant hurdle for this service. Most government departments would not let APM data (even de-identified) outside their firewall, particularly if it contains any server names.
How did our approach work? It's a data and model driven performance modelling and prediction tool. We capture APM data from APM vendors (e.g. Dynatrace), pre-process and transform this into data suitable to build models from, then automatically build, parameterise and calibrate performance models and run simulations to produce performance, scalability, and resource predictions. We can do this at the transactional level for fine-grained detail.
The way this works for Cloud migrations is that we obtain some baseline APM data from the systems running on the in-house platform, run the pre-processing and model building code, and then visualise the models and run the simulations in our SaaS tool. This can tell you what the performance of the current system (workloads, transaction mixes, software, platforms, etc) is. But then we can explore future possibilities taking into account changes including workload changes (distributions, spikes, etc), transaction mix changes (including new transaction types), architectural and software changes (e.g. changes to what components will deployed where and on what shared resources, what 3rd party services are used, etc), and changes to the platform (e.g. in-house physical bare metal hosts to AWS instances of different sizes, hybrid deployments, etc). Here are a couple of examples of migration projects we were involved in using this approach.
1 Migration of client applications from legacy physical servers to new in-house VM private cloud and/or public cloud options.
The problem involved a larger number of applications owned by clients but hosted by a telco in legacy physical infrastructure that was being retired. Customers (and the teloc) wanted to know what the performance and scalability impact would be depending on what the target they migrated to was, the impact of re-architecting and possible changes to workloads etc. We used Dynatrace to capture APM data from sample applications running on both the legacy hardware and the new VM private cloud, and some benchmarking results from AWS. We were able to build accurate performance models capturing the applications as it on all the platforms and validate the results and make predictions about performance, scalability and impact of re-architecting and other changes (including cost). For this project it was apparent that performance would be reduced for the private cloud, but scalability and cost would be improved. For AWS performance would be more variable, scalability better and cost better.
2 Cloud DevOps to in-house hosting for production.
This was a slightly odd migration problem as a government department already had their application running on AWS, but using fake data and only for User acceptance testing. The production version was to be run in-house on VM private-cloud, but they needed sufficient lead time to provision the servers (6-8 weeks before the deadline). We were able to collect Dynatrace data from the AWS test environment and build and calibrate models for the in-house hardware. Some of the challenges with this approach were that the user acceptance tests were low load, and not a representative transaction mix or workload, which we had to model by hand. The performance on the AWS infrastructure was poor and would have violated SLAs on the production version, and we had to do substantial data cleaning and error filtering to ensure the APM data was useful for calibration for the in-house hardware. Finally the error margin for the resource prediction for the in-house number of servers had a relatively high lower and upper bound making it difficult to predict an exact number of servers, eventually they had to over provision slightly in order to ensure sufficient resources at turn on (but with the ability to wind back).
Our data and model-based predictive analytics migration approach worked well when there was data of sufficient quality and quantify from an existing production system with Dynatrace installed. We could automatically model and visualise workloads (down to transaction type detail), applications, software and component dependencies and deployment details, and server information, along with performance data (workload arrival rate distributions, times per software component per transaction type per server, etc), The resulting models could be used to explore alternatives, including fine-grained changes in transaction mixes and software, and calibrated for different target infrastructures and server speeds/sizes/types. This approach could be used in DevOps as well to build models consisting of baseline production systems combined with changes resulting from new code ready for deployment, combined with say the worst case workload spike from last year. We have also used this approach to model the impact on SLAs and costs of load spikes and elasticity (e.g.Auto scaling, and managed services). A head-to-head comparison with AWS Application Discover Service would be interesting.
In summary our approach is more flexible as it can take into account changes between current and target system, and is finer grained (transactional, and breakdown times per transaction per software component including cpu, io, sync, wait, suspension). The resulting models are also more useable than just "data" and allow changes to be made and visualised, and predictions made, graphed in different ways, and compared across multiple alternatives.
In summary our approach is more flexible as it can take into account changes between current and target system, and is finer grained (transactional, and breakdown times per transaction per software component including cpu, io, sync, wait, suspension). The resulting models are also more useable than just "data" and allow changes to be made and visualised, and predictions made, graphed in different ways, and compared across multiple alternatives.
See our web site if you are interested in more details on modelling from APM data.



Want to change your career in Selenium? Red Prism Group is one of the best training coaching for Selenium in Noida. Now start your career for Selenium Automation with Red Prism Group. Join training institute for selenium in noida.
ReplyDeleteYour examples of migration projects are fascinating! I especially liked how you modeled performance down to transaction-level detail—it seems way more precise than relying solely on discovery agents. Has anyone tried applying this methodology to a high-scale DevOps CI/CD pipeline on AWS? I’d love to see real-world results.
ReplyDelete