AWS Solution Architect Certification More Practice Questions
1בְּרֵאשִׁ֖ית בָּרָ֣א אֱלֹהִ֑ים אֵ֥ת הַשָּׁמַ֖יִם וְאֵ֥ת הָאָֽרֶץ׃ 2וְהָאָ֗רֶץ הָיְתָ֥ה תֹ֙הוּ֙ וָבֹ֔הוּ וְחֹ֖שֶׁךְ עַל־פְּנֵ֣י תְהֹ֑ום וְר֣וּחַ אֱלֹהִ֔ים מְרַחֶ֖פֶת עַל־פְּנֵ֥י הַמָּֽיִם׃
In English:
1 In the beginning God created the heavens and the earth. 2 Now the earth was formless and empty, darkness was over the surface of the deep, and the Spirit of God was hovering over the waters.
And a Dead Letter (see below)

More questions and answers I didn't guess right (or maybe I did?) first time.
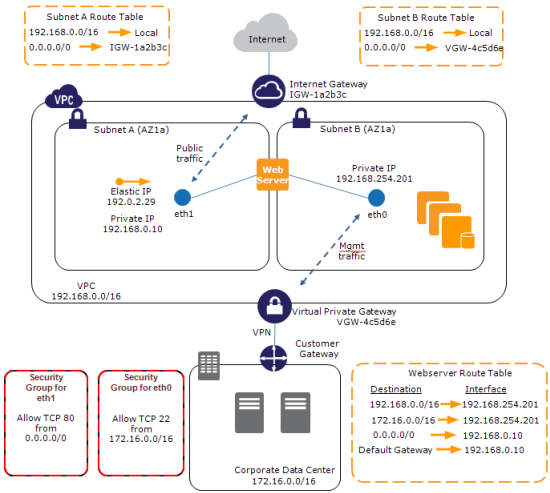
Q1 What is a VPC Elastic Network Interface (ENI) associated with?
They claim VPC subset is correct. I (and the docs) also think that EC2 instance is a possible answer.
You can create a network interface, attach it to an instance, detach it from an instance, and attach it to another instance. A network interface's attributes follow it as it is attached or detached from an instance and reattached to another instance. When you move a network interface from one instance to another, network traffic is redirected to the new instance.
I.e. both are correct, an ENI exists in a VPC and can be connected to 0 or 1 instances.
Each ENI lives within a particular subnet of the VPC (and hence within a particular Availability Zone) and has the following attributes:
- Description
- Private IP Address
- Elastic IP Address
- MAC Address
- Security Group(s)
- Source/Destination Check Flag
- Delete on Termination Flag
A very important consequence of this new model (and one took me a little while to fully understand) is that the idea of launching an EC2 instance on a particular VPC subnet is effectively obsolete. A single EC2 instance can now be attached to two ENIs, each one on a distinct subnet. The ENI (not the instance) is now associated with a subnet.
So an Instance can have 2 ENIs (more?) and be part of 2 (or more?) VPCs.
And a picture:
Q2 WHich policy for AWS CloudFormation ensures a resource is not deleted when the stack is deleted? I was sure this was a trick question. Deletion policy? Too obvious but correct.
What are all the CloudFormation policies 2 only? The only other one I can find is the creationpolicy.
When you provision an Amazon EC2 instance in an AWS CloudFormation stack, you might specify additional actions to configure the instance, such as install software packages or bootstrap applications. Normally, CloudFormation proceeds with stack creation after the instance has been successfully created. However, you can use a CreationPolicy so that CloudFormation proceeds with stack creation only after your configuration actions are done. That way you’ll know your applications are ready to go after stack creation succeeds.
A CreationPolicy instructs CloudFormation to wait on an instance until CloudFormation receives the specified number of signals. This policy takes effect only when CloudFormation creates the instance. Here’s what a creation policy looks like:
Q3: Which API provides AWS Trusted Advisor? Another trick question. I thought AWS Trusted Advisor. Wrong, correct answer is AWS Support. But the docs say:
The AWS Support API provides access to some of the features of the AWS Support Center. AWS provides this access for AWS Support customers who have a Business or Enterprise support plan. The service currently provides two different groups of operations:
- Support Case Management operations to manage the entire life cycle of your AWS support cases, from creating a case to resolving it.
- Trusted Advisor operations to access the checks provided by AWS Trusted Advisor
So if you don't have a business or enterprise support plan how do you access Trusted Advisor? I can't find a definitive answer for this TODO
Q4: Why should you use a DNS CNAME to reference a ELB?
The CNAME will not change giving you a single fixed addressing entry regardless of the pool of IPs referenced by the CNAME.
Ok, but there's another approach using Alias resource records sets, what's the difference? Darned if I know. But looks like you have this option for Route 53. This looks correct from a blog:
They are saying CNAME or Alias record. Use CNAME if you are using a non-Route53 DNS, but use Alias sets if you are using Route53 (unless you have a reason for wanting a really legacy setup).
Unfortunately this all looks like network systems admin gobbledegook to me! i.e. OED:
Language that is meaningless or is made unintelligible by excessive use of technical terms.
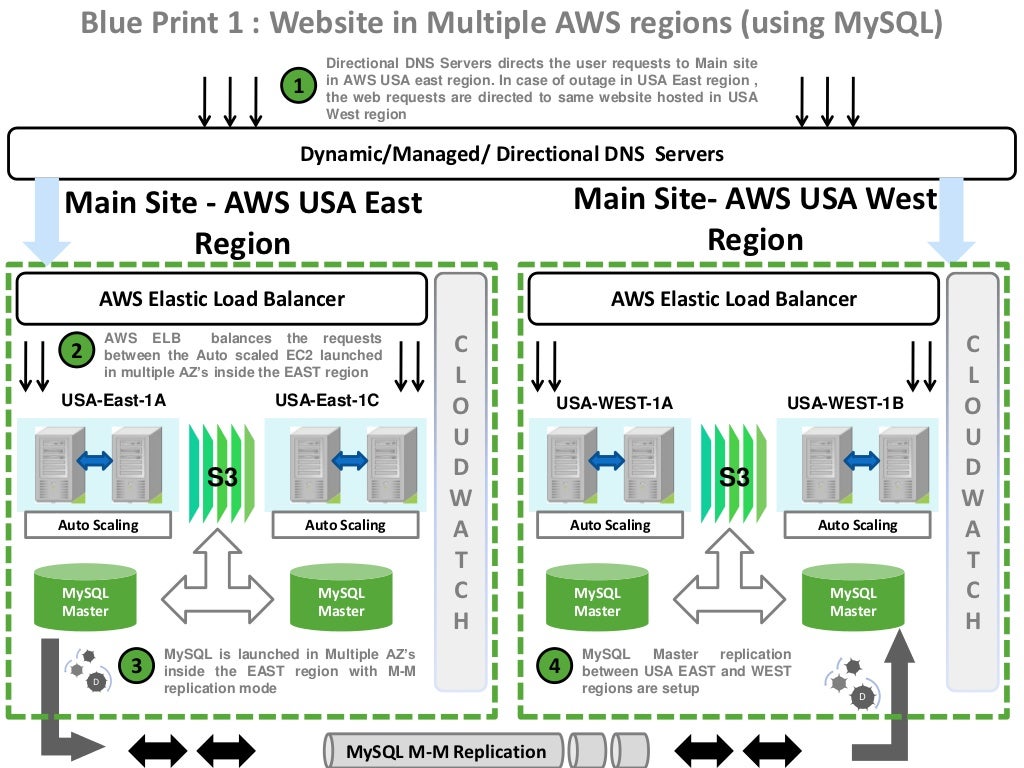
Q5: Which services are used to create HA applications on AWS? This one is sort of obvious but I get confused by how they all work together. And note that note of the 16 reference architectures mention CloudWatch in the context of HA (or any pattern). Odd.
Answer is CloudWatch, ELB and Auto Scaling (and maybe a few EC2 instances????)
And maybe even: AutoScaling, ELB, VPC, Route 53 and CloudFront. An older set of blueprints for HA across and within regions uses these services:

Across regions:
Within regions:
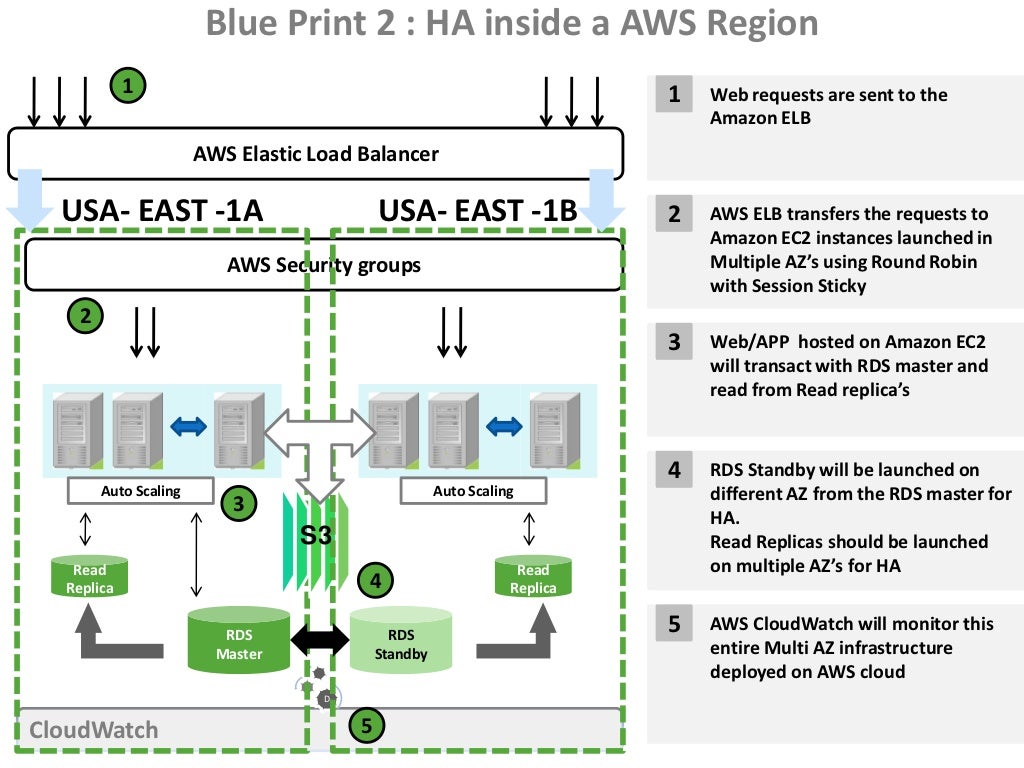
Within regions:
Q6: To take advantage of cloud parallelization what should you use?
Multi-threading OR Asynchronicity? (only 1 is allowed, really!)
Their answer is multi-threading. This is fine if you are thinking from a fine-grained HPC programming perspective, but NOT if you are thinking from an architecture and SOA, serverless event-driven perspective.
See AWS architecture best practices.
E.g.
Decoupling your components, building asynchronous systems and scaling horizontally become very important in the context of the cloud. It will not only allow you to scale out by adding more instances of same component but also allow you to design innovative hybrid models in which a few components continue to run in on-premise while other components can take advantage of the cloud-scale and use the cloud for additional compute-power and bandwidth. That way with minimal effort, you can “overflow” excess traffic to the cloud by implementing smart load balancing tactics.
The key is to build components that do not have tight dependencies on each other, so that if one component were to die (fail), sleep (not respond) or remain busy (slow to respond) for some reason, the other components in the system are built so as to continue to work as if no failure is happening. In essence, loose coupling isolates the various layers and components of your application so that each component interacts asynchronously with the others and treats them as a “black box”. For example, in the case of web application architecture, you can isolate the app server from the web server and from the database. The app server does not know about your web server and vice versa, this gives decoupling between these layers and there are no dependencies code-wise or functional perspectives. In the case of batchprocessing architecture, you can create asynchronous components that are independent of each other.
I.e. Asynchronicity is key to scale-out horizontally, which is what AWS cloud really is good at (using elasticity, event based asynchronous services and commodity hardware).
Q7: which is the most important benefit of cloud?!
Not having to rack and buy h/w, ability to move apps in and out of data centres you don't operate, use APIs to automate, you can order an espresso online, etc?
The "correct" answer is the last. Says who???? How about cost? Elasticity? Security? Flexibility? Reliability? Managed services? Large number of SaaS services? Innovation? Large numbers of instances on demand? Sure, automation is part of the story but not the whole story.
Q8: Which service can push notifications to mobile applications? This one is sort of obvious, SNS. But then I wondered how it does this? Turns out there are 2 SNS services:
SNS Pub/Sub which I knew about:

And SNS Mobile Notifications:

And combined:

Where did the SMS subscriber come from? Looks like SMS is another endpoint type.
As are Lambda Functions. And email.
To receive messages published to a topic, you have to subscribe an endpoint to that topic. An endpoint is a mobile app, web server, email address, or an Amazon SQS queue that can receive notification messages from Amazon SNS. Once you subscribe an endpoint to a topic and the subscription is confirmed, the endpoint will receive all messages published to that topic.
And Now For Some Random Number Qns!
Q8: What's max timeout for SQS visibility timeout? Think of a number...
Here's the docs:


Multi-threading OR Asynchronicity? (only 1 is allowed, really!)
Their answer is multi-threading. This is fine if you are thinking from a fine-grained HPC programming perspective, but NOT if you are thinking from an architecture and SOA, serverless event-driven perspective.
See AWS architecture best practices.
E.g.
Decoupling your components, building asynchronous systems and scaling horizontally become very important in the context of the cloud. It will not only allow you to scale out by adding more instances of same component but also allow you to design innovative hybrid models in which a few components continue to run in on-premise while other components can take advantage of the cloud-scale and use the cloud for additional compute-power and bandwidth. That way with minimal effort, you can “overflow” excess traffic to the cloud by implementing smart load balancing tactics.
The key is to build components that do not have tight dependencies on each other, so that if one component were to die (fail), sleep (not respond) or remain busy (slow to respond) for some reason, the other components in the system are built so as to continue to work as if no failure is happening. In essence, loose coupling isolates the various layers and components of your application so that each component interacts asynchronously with the others and treats them as a “black box”. For example, in the case of web application architecture, you can isolate the app server from the web server and from the database. The app server does not know about your web server and vice versa, this gives decoupling between these layers and there are no dependencies code-wise or functional perspectives. In the case of batchprocessing architecture, you can create asynchronous components that are independent of each other.
I.e. Asynchronicity is key to scale-out horizontally, which is what AWS cloud really is good at (using elasticity, event based asynchronous services and commodity hardware).
Q7: which is the most important benefit of cloud?!
Not having to rack and buy h/w, ability to move apps in and out of data centres you don't operate, use APIs to automate, you can order an espresso online, etc?
The "correct" answer is the last. Says who???? How about cost? Elasticity? Security? Flexibility? Reliability? Managed services? Large number of SaaS services? Innovation? Large numbers of instances on demand? Sure, automation is part of the story but not the whole story.
Q8: Which service can push notifications to mobile applications? This one is sort of obvious, SNS. But then I wondered how it does this? Turns out there are 2 SNS services:
SNS Pub/Sub which I knew about:
And SNS Mobile Notifications:
You send push notification messages to both mobile devices and desktops using one of the following supported push notification services:
- Amazon Device Messaging (ADM)
- Apple Push Notification Service (APNS) for both iOS and Mac OS X
- Baidu Cloud Push (Baidu)
- Google Cloud Messaging for Android (GCM)
- Microsoft Push Notification Service for Windows Phone (MPNS)
- Windows Push Notification Services (WNS)
And combined:
Where did the SMS subscriber come from? Looks like SMS is another endpoint type.
As are Lambda Functions. And email.
To receive messages published to a topic, you have to subscribe an endpoint to that topic. An endpoint is a mobile app, web server, email address, or an Amazon SQS queue that can receive notification messages from Amazon SNS. Once you subscribe an endpoint to a topic and the subscription is confirmed, the endpoint will receive all messages published to that topic.
And Now For Some Random Number Qns!
Q8: What's max timeout for SQS visibility timeout? Think of a number...
Here's the docs:
Each queue starts with a default setting of 30 seconds for the visibility timeout. You can change that setting for the entire queue. Typically, you'll set the visibility timeout to the average time it takes to process and delete a message from the queue. When receiving messages, you can also set a special visibility timeout for the returned messages without changing the overall queue timeout.
If you don't know how long it takes to process a message, specify the initial visibility timeout (for example, 2 minutes) and the period of time after which you can check whether the message is processed (for example, 1 minute). If the message isn't processed, extend the visibility timeout (for example, to 3 minutes).
When you receive a message for a queue and begin to process it, the visibility timeout for the queue may be insufficient (for example, you might need to process and delete a message). You can shorten or extend a message's visibility by specifying a new timeout value using the
ChangeMessageVisibility action.
For example, if the timeout for a queue is 60 seconds, 15 seconds have elapsed, and you send a
ChangeMessageVisibility call with VisibilityTimeout set to 10 seconds, the total timeout value will be the elapsed time (15 seconds) plus the new timeout value (10 seconds), a total of 25 seconds. Sending a call after 25 seconds will result in an error.
Sounds complex. So what's the max value? Why should there be a max value? Is there a max time that messages are retained in SQS? It could be that...
Maybe the visibility timeout maximum is the same? No, it's 12 hours!
The maximum allowed timeout value is 12 hours. Why? Who knows. Who cares???
Q9: How many tunnels are established for a VPN between CGW and VPG? Think of another number...
2? Correct. This is all very specific, see the docs.
You use a VPN connection to connect your network to a VPC. Each VPN connection has two tunnels, with each tunnel using a unique virtual private gateway public IP address. It is important to configure both tunnels for redundancy.
The following diagram shows the two tunnels of each VPN connection and two customer gateways.
Q10: What's a Dead Letter queue for? I got this one right, but again pretty specific.
What are the Benefits of Dead-Letter Queues?
The main task of a dead-letter queue is handling message failure. A dead-letter queue lets you set aside and isolate messages that can’t be processed correctly to determine why their processing didn’t succeed. Setting up a dead-letter queue allows you to do the following:
- Configure an alarm for any messages delivered to a dead-letter queue.
- Examine logs for exceptions that might have caused messages to be delivered to a dead-letter queue.
- Analyze the contents of messages delivered to a dead-letter queue to diagnose software or the producer’s or consumer’s hardware issues.
- Determine whether you have given your consumer sufficient time to process messages.
The idea has been around in MOM for a while, but it's hard to find the original computer science origins. Maybe this paper from IBM in 1999. It may have been in use prior to this and not documented.
Note, that in practice this processing is a bit more subtle: Although the message queuing
system guarantees to never loose a message the reception of which it acknowledged it might
happen that it cannot deliver the message to the specified target queue. For example, the
target queue might not exist, it might be full etc.. Also, the message might be “poisoned”, i.e.
the server might always end abnormally when trying to process the message. In these and similar cases the subject message is delivered into a so-called “dead letter queue” from which
it can be processed by a special program (e.g. the message can be analyzed, perhaps corrected,
and send again). In this sense, message integrity does not ensure exactly once processing but
at most once processing (e.g. if the message cannot be corrected) with precise exception
semantics.
Q11: What type of storage is the z:\ drive? Doesn't it depend? I thought so.
The correct answer was "instance storage". Is that always the case? I'm not sure...
Device Name Considerations
Keep the following in mind when selecting a device name:
- Although you can attach your EBS volumes using the device names used to attach instance store volumes, we strongly recommend that you don't because the behavior can be unpredictable.
- Amazon EC2 Windows AMIs come with an additional service installed, the Ec2Config Service. The Ec2Config service runs as a local system and performs various functions to prepare an instance when it first boots up. After the devices have been mapped with the drives, the Ec2Config service then initializes and mounts the drives. The root drive is initialized and mounted as
C:\. The instance store volumes that come attached to the instance are initialized and mounted asZ:\,Y:\, and so on. By default, when an EBS volume is attached to a Windows instance, it can show up as any drive letter on the instance.
Given that:
By default, when an EBS volume is attached to a Windows instance, it can show up as any drive letter on the instance.
It could show up as a z:\?
The answer was "deploy new instances with detailed monitoring enabled". I assumed you could change CloudWatch alarms for a specific instance.
I.e. the docs say:
By default, your instance is enabled for basic monitoring. You can optionally enable detailed monitoring. After you enable detailed monitoring, the Amazon EC2 console displays monitoring graphs with a 1-minute period for the instance.
And this says:
To enable detailed monitoring for an existing instance using the console
- Open the Amazon EC2 console at https://console.aws.amazon.com/ec2/.
- In the navigation pane, choose Instances.
- Select the instance, choose Actions, CloudWatch Monitoring, Enable Detailed Monitoring.
- In the Enable Detailed Monitoring dialog box, choose Yes, Enable.
- Choose Close.
So, I think the answer is incorrect. You DON'T need to deploy new instances at all. You only have to enable detailed CloudWatch monitoring for the instance.
Q13: Your company maintains a photo library with 100 million photos available for licensing. The total storage requirement for the photos themselves is 200 GB. There is also a low-resolution version of each photo generated, with those versions taking up a total of 10 GB. Your company runs on very low margins, so minimizing cost is important. What is a cost-effective way to store all your photos?
This one was tricky as you have to make some assumptions about the app. For example, the low-resolution versions can be regenerated, people want the high-res versions immediately they buy them, and that RRS is actually cheaper than standard storage. It's not, it's now more expensive.
The "correct" answer was originals on S3 (standard) and low-res on RRS.
In fact none of the answers are any good now.
Actually one may be ok: Originals on S3 and low-res on EBS? Yes, similar price.
RRS option costs 26c/month (excluding I/O), EBS is 30c/month (including IO, so may be cheaper).



Want to change your career in Selenium? Red Prism Group is one of the best training coaching for Selenium in Noida. Now start your career for Selenium Automation with Red Prism Group. Join training institute for selenium in noida.
ReplyDelete